一个典型的Web架构中,网关是一个很容易被忽略的东西,或者透明般存在,而在云原生的微服务架构中,网关被赋予了更多职责,也变得更为重要。
1、反向代理时代
说到反向代理,不得不提Nginx,开源版的Nginx也仅起到反向代理的作用,常用来根据Host,Path来路由到不同的服务,做Stream负载均衡,SSL终结等,流量基本是透传,所以在后端看来几乎透明。且通过配置文件进行管理,一旦服务多了,难以维护。优势也就占用资源少,性能强悍。
2、边缘网关时代
在云原生时代,微服务众多,接入设备复杂多样化,一些重复度高的动作就必须抽取出来,而这些琐碎放到网关在合适不过了,以Apigee Edge为例,支持公有云、混合云、私有云部署,不仅做到API管理,还支持客户端管理,顶级层级为APP(Mobile or Web),可配置访问凭证,第二层级为Products,可配置环境(SIT or PROD),授权给APP访问,第三层级为API Proxies,即下面详解的API管理,绑定到Products,三层按顺序均为一对多关系,可参考OAuth2授权模式之密码模式。
API Proxy主要抽象出几个概念:
1、代理端点(Proxy Endpoints)
2、目标端点(Target Endpoints)
3、策略(Policies)
4、资源(Resources)
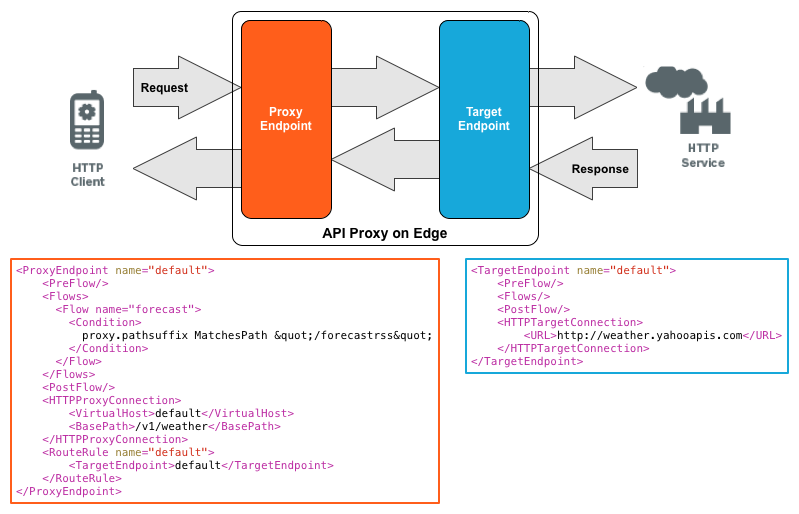
代理端点用来定义一个API,并对外暴露,主要与客户端打交道,目标端点则可以是后端微服务,也可以是公网上的另一个API,API支持环境区分部署,版本管理。
策略则是Apigee精华所在,策略是对请求做处理的最小单元,例如定义一个策略对参数进行校验、再定义一个对user&app token校验等,甚至执行js&java lib进行加解密等更为复杂的逻辑。策略通过Flow(处理流)来规定执行条件和执行顺序,一旦命中则跳过后续Flow。多个Flow又可以组成Shared Flows,以便复用。同样Flow也支持环境区分部署,版本管理。
资源则是放置js脚本或者java lib的地方,供策略调用。策略支持分环境来部署,支持版本切换,而这一切都是动态实时的,无需重启reload。
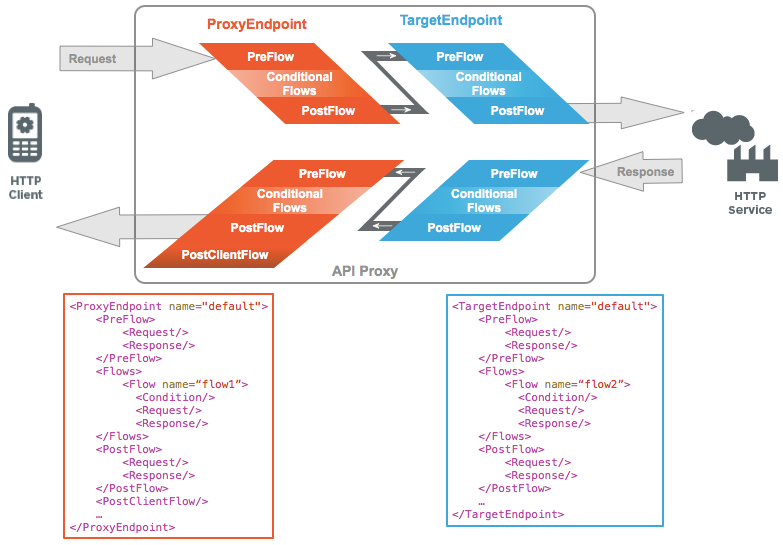
这样一来,到达backend的请求就已经是符合要求的了,可以省去很多的判断。
这里继续介绍一下策略,策略实质上是通过xml来定义,可分以下几种:
1、流量管理,例如Quota、Spike Arrest等,内置了数十种对流量进行管理的策略。
2、安全管理,例如Basic Authentication、OAuth、LDAP、JWT、HMAC等,同样内置了十分丰富,涵盖大部分场景。
3、协调与扩展,例如内置的XML&JSON格式互转。其中用的比较多的主要以下三个,可以非常灵活的将多个backend请求组合成一个API。
3.1、AssignMessage 请求管理
3.2、ServiceCallout 外部服务调用
3.3、ExtractVariables 解析响应
Apigee使用几个月来,初期学习成本比较高,但很多配置都是复用的,后续维护并不算太难。当然有了如此强大的功能,还有配套的trace工具,可视化的看到每一个请求的执行情况、入参和出参、请求头、策略命中与结果等,非常人性化,Apigee简单介绍到此,更详细请查阅官方文档,后续再对比一些开源方案。
文档地址:https://docs.apigee.com/api-platform/get-started/get-started