就在昨天儿童节的时候,大概9点半左右收到微信公众号的报警信息,发现是服务器没有响应,5分钟内6次请求没有及时返回。当时并没有过多在意,因为之前也有过1~2次失败,都是是偶然因素。过了几分钟又收到dnspod的邮件报警,内容是snapast.com主站连接超时,这才意识到可能服务器宕机了。
立刻手动访问一次,果然是打不开了,ssh也连接不上,下意识认为可能是服务器被重启了,因为之前托管在linkcloud的时候,隔个把月总会挂掉一下,但迁移到阿里云后一直很稳定,不太会出问题。
登录到阿里云后台,在实例监控看到CPU一直满负荷运行,入网流量达到22M/s(云盾基础防护中显示有接近30M/s,忘了PPS多少来着),出网也已经塞满2M带宽。

通过阿里的终端登录到主机上,发现CPU是被4个nginx进程占满,后端几个tomcat负载并不高,说明并不是一般的大规模http请求(cc攻击)。而且nginx access log也是正常,但error log有很多xxx worker_connections are not enough,说明确实连接数较高,超过设定值。通过netstat统计居然有1.6w左右的连接数,远高于平时的300左右。
root@snapast:~# netstat -an | wc -l 16089
到这里基本能判断极有可能是SYN Flood,想到云盾有一定抵抗DDOS的能力,试着开启流量清洗看看,原来人家的默认触发条件是流量100M/s,PPS是1w,我这点攻击还没办法触发呢,于是手动设置了一个最低条件达到10M/s就开始清洗,然而事实证明清洗毫无用处,依旧连接超时。但有个好处是开始清理后可以抓包。
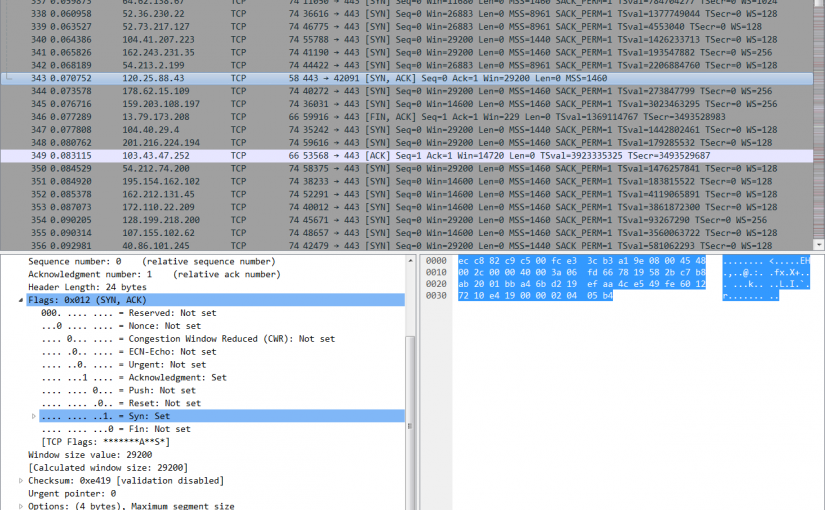
下载cap到本地用Wireshark打开一看,好家伙,果然是SYN握手攻击,大量的不同IP(美国为主)往443端口发SYN请求,极少数有回应RST,我猜应该是上层路由回的。云盾的抓包并不是你主机网卡包,而是在接入口的设备上。这下明了了,对于这种TCP层的攻击也没啥好办法抵御的,考虑到目前仅有相册用了https,所以先停掉nginx监听443端口,将机器负载降了下来,但也没办法彻底解决。有意思的是当时阿里云解析也出了故障没办法修改域名解析,屋漏偏逢连夜雨。

就这么瞎折腾了2个小时,攻击才停止,一切也都恢复正常。今天来看,在微信接口调用统计中失败次数最为“壮观”的一天。
现在想想其实也有一些办法可以减小宕机损失:比如将受攻击的域名临时解析到别处。再如将多个业务分离开来,用不同的域名,不同的IP接入,iptables将多次密集连接请求的IP drop掉。